
June 2026 - The growing interest in AI and IoT is giving rise to new initiatives and experimentation. In this interview, we hear from student researcher, Eunjin Lee, about a project that combines federated AI and IoT.

Q: Would you begin with by introducing your background and research interests?
EL: My name is Eunjin Lee, and I am an undergraduate student in the Department of Information Security at Sejong University in South Korea.
Currently, I am working as an undergraduate researcher at the Software Engineering and Security Lab, SESLab, led by Professor JaeSeung Song. In the lab, my research focuses on oneM2M-based IoT platforms and the practical application of artificial intelligence technologies to IoT environments.
I am especially interested in how AI can be used to solve real security, IoT, and industrial problems. I am currently involved in an industrial machinery project that combines AI and IoT.
Q: What is the goal of the “AI-IoT” project and what issues are you are trying to solve?
EL: The goal of this project is to detect bearing faults in factory machines before they lead to serious failures or accidents.
AI is useful for this, but there are two main challenges. First, factory data can contain sensitive business information, so companies may not want to send it outside their own site. Second, each factory might have different machine conditions, so data from only one site may not be enough to train a reliable AI model that works across all sites.
To solve this problem, we are testing a federated learning approach. This allows several sites to train an AI model together without sharing their raw data. We implemented this approach on top of oneM2M, which is an open standard, IoT platform.
Q: Would you explain what is meant by federated learning?
EL: Federated learning is a way to train an AI model without collecting all the data from a family of machines in one central place. In traditional AI training, data from many places is gathered into one server. In federated learning, the data stays where it is, for example, inside each factory. Each site trains a local AI model using its own data, and only the model parameters, such as weights, are sent to a central server.
A simple example is students studying at home separately and only sending their test results to the teacher. The teacher then combines the results to understand the overall learning outcome.
Q: What is a simple explanation of how AI helps in bearing fault detection?
EL: Firstly, we need data from our connected machine. For this, we attach acceleration sensors to the bearings and collect vibration signals. In our project, we collect 2,560 data points every 0.1 seconds. This means the sensor measures vibration 25,600 times per second.
A normal bearing usually has a stable vibration pattern. For example, the root mean square (RMS) value, which represents vibration strength, is usually around 0.3 to 0.5 g. However, when wear or cracks begin to appear, the vibration level starts to increase and can go above 1.0 g.
We used 1.0 g as the fault threshold, instead of the manufacturer’s official 20 g threshold. The reason is that 20 g usually means the bearing is already seriously damaged, so it is too late for early detection. Our goal was to detect early warning signs before complete failure.
Q: How is federated learning a useful technique in this bearing fault detection situation?
EL: Federated learning is useful because factory data is often sensitive and difficult to share. It may include information about machine conditions, production processes, or operational patterns.
In industrial IoT settings, federated learning also solves the cold start problem. A newly deployed factory with no failure history cannot train a reliable, anomaly detection model on its own. By joining a federated learning process, the new factory receives a globally trained model that captures failure patterns from other factories. That makes effective predictions possible from day one without exposing any raw data.
In our system, we used three nodes with different operating conditions: 1800 rpm, 1650 rpm, and 1500 rpm. Each node trained its own model using local vibration data, without sending the raw data to the server. Then, the server combined the model updates to create a better global model.
This approach allowed us to protect data privacy while still learning from different machine conditions.
Q: Would you describe the system architecture and key components?
EL: Let me begin by describing our use case which involves three factories: Factory A, Factory B, and Factory C. Each operates independently and each one collects sensor data from their manufacturing equipment. There is a factory gateway for each factory to store local sensor data and to communicate with the central, cloud platform. Factory A and Factory B have sufficient historical failure data to train local models. Factory C is a newly added factory. It has no failure history and faces the cold start problem. The cloud platform aggregates local model updates, by uploading data from each factory, to produce a global model which it then distributes back to the factories.
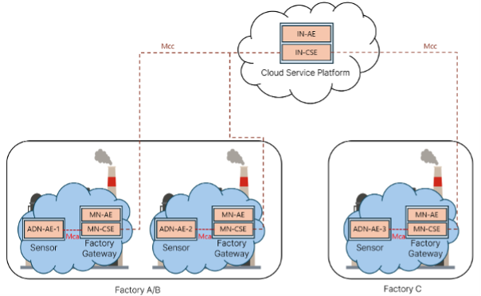
The architecture diagram shows the three factories and central cloud service platform. Using oneM2M terms, we label sensor nodes at each factory as Application Dedicated Nodes (ADNs). The AE (Application Entity) part of each sensor node refers to the application logic, which is responsible for processing sensor measurements. The architectural diagram shows these sensor components and their unique identifiers, ADN-AE-1, ADN-AE-2, and ADN-AE-3.
Next, there is an MN-AE (middle-node, application entity) at each factory site. These MN-AEs have local processing capacity. They function as gateways or edge nodes, collecting sensor data locally and training a local AI model.
At the centre of the system, there is an IN-AE (Infrastructure Node, Application Entity), which works as the system coordinator. In oneM2M terms, the infrastructure label refers to the domain where servers and applications on large computers are located. The IN-AE receives model updates from the factory gateway nodes. It then aggregates them into a global model.
The process of routing communications between AEs involves a CSE (common service entity). In our case, we use tinyIoT which is a oneM2M middleware platform or CSE. The CSE provides several enabling functions. These include HTTP and CoAP protocol bindings as well as functions to enable subscription and notification, and access control.
Once the IN-AE publishes a training command, each MN-AE uploads the updates made to its local model. After that, the IN-AE distributes the aggregated global model. We display real time results through a Flask-based web dashboard.
In our implementation, the whole system runs on Windows with WSL2 (Windows subsystem for Linux). The system uses five independent processes: one IN-AE, three MN-AEs, and one dashboard.
Q: What are the steps in the training and model distribution process?
EL: I can explain the process in terms of a oneM2M resource tree model as shown in the accompanying illustration. This consists of TinyIoT, which is present in the IN-CSE (the cloud IoT platform part) and in the MN-CSE (the field gateway platform). The IoT cloud platform is the system coordinator, and the field gateway handles local model training. This is a simplified diagram as our system contains three MN-CSEs, one for each factory.
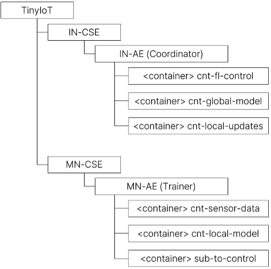
Focusing on one factory and its connected machine, each MN-AE has a <container> to store per-round, sensor data slices There is a <container> to cache local model metadata which prevents duplicate training within a round. There is also an MN-AE <container> which holds a subscription setting to the cnt-fl-control <container> flag. The subscription setting notifies the MN-AE when cnt-fl-control flag changes. oneM2M’s subscription and notification function avoids the need for constant polling to check for changes; instead, a subscribing entity can respond once it receives notification of a change.
When the IN-AE publishes a training start command, each MN-AE trains a local model using its own normal bearing vibration data.
After local training, each MN-AE uploads its model parameters to cnt-local-updates. The IN-AE then collects the updates from the three nodes and combines them using FedAvg, which is a common federated learning aggregation method.
The new global model is then uploaded to cnt-global-model, and each MN-AE downloads it to start the next training round.
We repeat this process for ten rounds. During this process, the MN-AE3 node also monitors incoming bearing signals in real time to detect possible faults.
Q: With this setup, how does the fault detection process work?
EL: There are two main phases of operation to think about: the training phase, and the monitoring phase.
In the training phase, we train a Conv1D autoencoder using only normal vibration signals. An autoencoder learns how to compress and reconstruct data. If the input signal is normal, the model can reconstruct it well. If the signal is abnormal, the model cannot reconstruct it accurately.
In the monitoring phase, the system takes real-time vibration signals and tries to reconstruct them using the trained model. Then, it calculates the reconstruction error using MSE (mean square error).
The anomaly threshold is automatically set using the mean plus three times the standard deviation of the validation MSE that is obtained from normal data. If the reconstruction error exceeds this threshold three times in a row, the system raises a fault alarm.
Q: How does fault detection show up on your system dashboard”
EL: The illustration below shows the dashboard. The top bar contains a tile for each node from mn1 to mn3. We colour code the tiles using green for normal operations, blue for training, and red when a fault is reported.
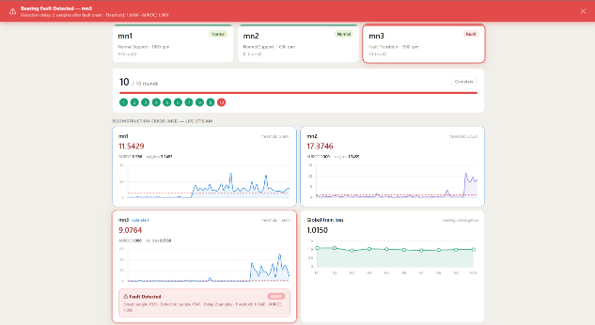
The next horizontal tile shows how many rounds of training have occurred. In this case, the red circle indicates we are in round ten.
Below this tile, there is a two-by-two panel which is the Reconstruction Error Chart. The data here shows the moment of fault detection. In mn3, the first abnormal signal appears at sample 339. The system raises an alarm at sample 341, after the anomaly threshold is exceeded three times in a row. This means the fault was detected only two samples after the first abnormal signal.
Q: How would you summarize your findings from the project?
EL: After ten rounds of federated learning, the model clearly distinguished normal and abnormal vibration signals in our experiment. For mn3, which was the main target node for fault detection, the detection delay was zero samples. In other words, the system detected the fault immediately when it occurred.
The most important finding is that we achieved this result without sharing raw data between nodes. This shows that federated learning can be practically useful for distributed fault detection in IoT and industrial environments.
Q: What further work can be done with this project?
EL: There are several possible directions for future work. First, our current system mainly detects whether the signal is normal or abnormal. In the future, it could be extended to classify the type or location of the fault, such as whether the damage is on the inner race, the outer race, or on rolling element of the bearing.
Another research direction is to predict the useful remaining life of a machine component. This means estimating how many hours are left before a machine is likely to fail.
Also, since each factory may have different operating conditions, “personalized” federated learning could be useful. Each node could start from the global model and then fine-tune that model for its own environment.
In this project, we applied federated learning by using existing oneM2M resources. However, for federated learning to be used more consistently and interoperably in the future, it would be important to define new, dedicated oneM2M resources for federated learning and to propose them to the standardization body.
Further research and development should focus on using these dedicated resources so that anyone can more easily deploy and use federated learning through the oneM2M platform.
Finally, we need more testing with a larger number of nodes. It would also be important to make the model lighter so that it can run on factory devices that operate with limited computing power.
Q: As you approach the end of this project and graduation, what are your next plans?
EL: I still have one semester left before graduation, but I have already started working in the field of security consulting. Security has been my long-time area of interest. Through several projects, I realized that future security problems will be difficult to solve without a good understanding of AI. That is one of the reasons why I became involved in this research project.
After graduation, I would like to gain more practical experience, but I am also interested in pursuing a master’s degree to study this field more deeply. I am especially interested in topics such as AI-based anomaly detection, privacy-preserving AI, IoT security, and security governance, where technology meets real industrial needs.
In the long term, I would like to become someone who understands both research and practice. My goal is not only to study new security technologies, but also to help companies and organizations apply them safely in real-world environments.
Q: Where can readers get more information about this project?
EL: I am in the process of finalizing my project report so that is not currently available. Readers can get more information from a Developer Guide that oneM2M members are producing. There is a draft technical report on oneM2M’s git repository - TR-0084 - Developer guide; Use of oneM2M resources to support Federated Learning.
Readers can also get more information and usage instructions about tinyIoT on our lab’s github repository.